递归导读
在python基础教程中,我已经写过一篇介绍递归函数的文章《递归函数》,在这篇文章,我详细的讲解了递归函数的编写方法,在进阶教程里,我将继续深入研究递归函数。
《python函数的调用过程》 将向你解释递归函数调用过程中,如何保存上下文,准确的说如何保存函数的信息,这包括当前局部作用域变量的值,函数当前执行到哪一行,运行的是哪个脚本。了解这些内容,有助于你理解为什么递归函数不能无限次的调用。
《python尾递归》 将向你介绍一种特殊的递归方式,以及如何通过这种递归来优化递归的性能,避免RecursionError
函数的调用过程
1. 函数调用
函数的执行过程从表面上看只是被调用的过程,但它的背后却是用栈这种数据结构实现的。理解了函数的调用过程,递归也就变得容易理解。
下面用一段代码来展示函数的调用
def a(): |
执行代码,输出结果
进入函数a |
函数a的执行过程分为3个步骤:
- print(“进入函数a”)
- c() 执行函数c
- print(“函数a执行结束”)
这段代码很简单,但却隐藏着初学者所不知道的秘密,这也是本文所要讲解的重点,首先请你思考一个看起来有点无聊的问题,为什么在执行完第2步以后,会执行第3步,输出”函数a执行结束”,而不是在执行完函数c以后,来到函数b中执行print(“函数b执行结束”)?
你当然可以回答,这是因为代码调用了函数a,所以函数c执行后要返回到a中而不是返回到函数b中。这个解释很合理,但是并没有说明根本原因,为什么函数c执行结束后要回到函数中,而不是函数b中?换一种问法,如果单独执行函数c,函数执行结束后既不会回到函数a,也不会回到函数b,为什么在函数a中执行函数c,函数c直接结束后就要回到函数a呢?
2. 函数调用与栈
在函数a中调用函数c,函数c执行结束后程序要回到函数a中继续执行,我们可以大胆猜测,一定是在某个地方记录了是在函数a中调用执行了函数c,所以才能准确的找到回去的路线,这个记录函数调用信息的地方就是栈。
栈是一种先进后出的数据结构,本文需要你对栈这种数据结构有一定的了解,否则,接下来要讲述的内容你很难理解。
在调用函数时,解释器会将函数的调用信息保存到栈中,这些保存的信息包括:
- 函数在第几行代码被执行
- 函数所在脚本
- 函数里的局部变量
在python中,可以通过sys._getframe()来查看这些信息
import sys |
我在函数c的第2行代码设置断点并进行调试,通过观察变量frame可以获得函数的调用信息,代码输出结果为
<code object c at 0x10f65e660, file "/Users/kwsy/kwsy/coolpython/demo2.py", line 11> 13 {'c_frame': <frame object at 0x10f6395d0>, 'count': 1} |
- f_code 保存代码信息
- f_lineno 保存当前函数执行到第几行,也叫函数返回地址
- f_locals 保存当前函数局部变量
函数的调用信息保存在frame结构中,通过f_back可以获得上一层函数的调用信息。
3. 函数调用过程
在调用函数时,会将当前信息保存到栈中,这其中就包括当前执行到第几行(f_lineno),当前的上下文环境(f_locals),当函数执行结束后,解释器则根据这些信息进行调度,它要根据f_lineno找到下一行要执行的代码,同时根据f_locals来还原现场。仍然以第2小节中的内容来透视函数的调用过程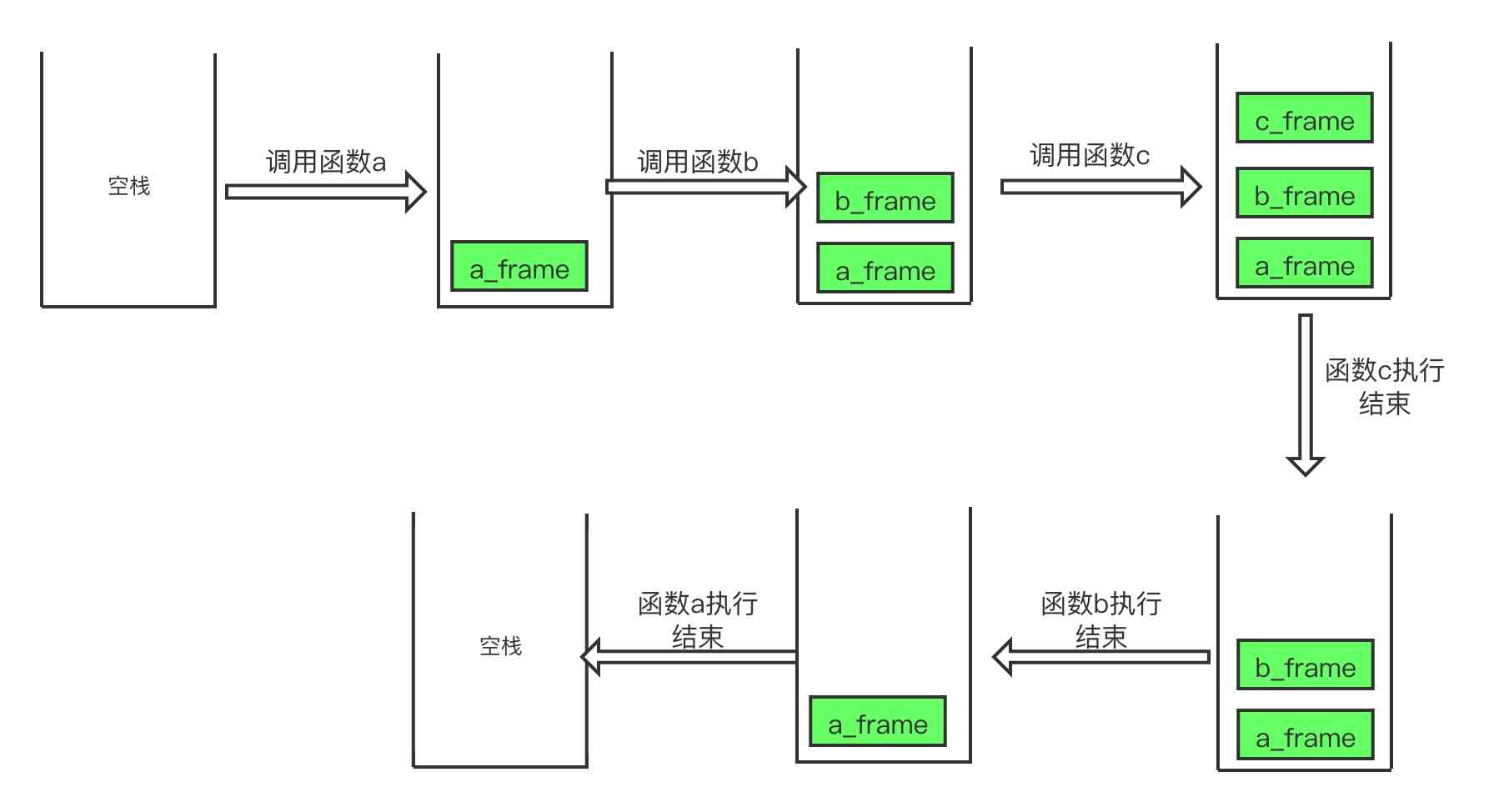
函数逐个调用的过程中,每一次调用都会向栈里压如一次有关函数调用的信息,这其中最重要的就是f_lineno 和 f_locals,一个记录当前函数调用发生在第几行,一个记录当前环境下的变量信息,前者是为了在函数执行结束后找到回来的位置,后者是为了回来以后还原上下文环境。
当c函数执行结束后,栈顶的c_frame被移除,此时栈顶保存的信息是b_frame,b_frame保存的信息包括
<code object b at 0x10f659db0, file "/Users/kwsy/kwsy/coolpython/demo2.py", line 7> 8 {'count': 2} |
通过frame里信息可以得知,上一次函数调用发生在demo2.py的第8行,因此下一行代码应该执行第9行代码,通过f_locals得知,count的值应该是2,利用f_locals里的信息,还原了现场环境,最终print(count)的输出结果是2
尾递归
1. 栈的深度限制
通过上一篇《函数的调用过程》,你现在已经知道函数调用执行过程中要使用到栈这种数据结构。关于存储函数调用信息的栈,你要知道一点,它的深度是有限制的,也就是说,你不能无限制的向里面放函数的信息,大多数时候,栈的深度可以满足我们的日常要求,但是如果碰上递归就不好说了,递归的过程就是函数调用自身,具体调用多少次,取决于算法,咱们以简单的斐波那契数列为例
import sys |
sys.getrecursionlimit() 返回的是python中对栈的深度限制,执行这段代码,很快就会报错
RecursionError: maximum recursion depth exceeded in comparison |
由于递归的次数太多了,所以超出了栈的深度限制
2. 尾递归
如果递归调用是子过程的最后一步,那么就是尾递归,上面的代码不是尾递归,因为计算fib(n)总是要先得到fib(n-1)和fib(n-2),下面的代码是一个尾递归
def tail_fib(n, a, b): |
3. 利用尾递归突破栈深度限制
函数调用过程中,相关信息都保存在了栈中,对于尾递归同样如此,但是对于尾递归来说,每一次调用自身时,之前保存的那些信息都没有使用价值了,道理就在于tail_fib执行结束之后,直接return了,根本不需要回到上一次调用它的函数中继续执行什么,所以先前放入栈中的信息都是没有价值的,那么如果能利用那些旧的栈空间,就可以在不增加栈的深度的情况下放入新的函数调用信息。
下面的代码是从一篇文章借鉴而来,遗憾的是这个网址已经无法访问了,为表示对原作者的尊重,仍既然将地址放在这里
http://cyrusin.github.io/2015/12/08/python-20151208/ |
通过sys._getframe()获得了函数的帧栈信息,如果当前帧的代码和前一个帧的前一个帧的代码相同,就说明递归调用已经发生了2次,那么此时就抛出一个异常。
这里有一个很关键的点要搞清楚,当我们执行tail_fib(100005, 0, 1)时,tail_fib是被tail_call_optimized装饰过的函数,当执行return func(*args, **kwargs)时,所执行的是没有被装饰过的函数,而在函数内部调用return tail_fib(n-1, b, a+b)时,tail_fib是被装饰过的函数。
整个执行过程如下:
- 执行tail_fib(100005, 0, 1)
- 判断f.f_code == f.f_back.f_back.f_code,不抛异常
- 执行return func(*args,**kwargs),进入函数tail_fib
- 执行return tail_fib(n-1, b, a+b),进入被装饰后的函数
- 判断f.f_code == f.f_back.f_back.f_code 抛异常
- 捕获异常,得到参数,执行return func(*args, **kwargs),进入函数tail_fib
- 执行return tail_fib(n-1, b, a+b),注意a+b,每次都进行了计算
- 判断f.f_code == f.f_back.f_back.f_code,抛异常
重复6, 7, 8 三个步骤。